Tutorial: Overfitting and Underfitting
In two of the previous tutorails — classifying movie reviews, and predicting housing prices — we saw that the accuracy of our model on the validation data would peak after training for a number of epochs, and would then start decreasing.
In other words, our model would overfit to the training data. Learning how to deal with overfitting is important. Although it’s often possible to achieve high accuracy on the training set, what we really want is to develop models that generalize well to testing data (or data they haven’t seen before).
The opposite of overfitting is underfitting. Underfitting occurs when there is still room for improvement on the test data. This can happen for a number of reasons: If the model is not powerful enough, is over-regularized, or has simply not been trained long enough. This means the network has not learned the relevant patterns in the training data.
If you train for too long though, the model will start to overfit and learn patterns from the training data that don’t generalize to the test data. We need to strike a balance. Understanding how to train for an appropriate number of epochs as we’ll explore below is a useful skill.
To prevent overfitting, the best solution is to use more training data. A model trained on more data will naturally generalize better. When that is no longer possible, the next best solution is to use techniques like regularization. These place constraints on the quantity and type of information your model can store. If a network can only afford to memorize a small number of patterns, the optimization process will force it to focus on the most prominent patterns, which have a better chance of generalizing well.
In this tutorial, we’ll explore two common regularization techniques — weight regularization and dropout — and use them to improve our IMDB movie review classification results.
##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionDownload the IMDB dataset
num_words <- 1000
imdb <- dataset_imdb(num_words = num_words)
c(train_data, train_labels) %<-% imdb$train
c(test_data, test_labels) %<-% imdb$testRather than using an embedding as in the previous notebook, here we will multi-hot encode the sentences. This model will quickly overfit to the training set. It will be used to demonstrate when overfitting occurs, and how to fight it.
Multi-hot-encoding our lists means turning them into vectors of 0s and 1s. Concretely, this would mean for instance turning the sequence [3, 5] into a 10,000-dimensional vector that would be all-zeros except for indices 3 and 5, which would be ones.
multi_hot_sequences <- function(sequences, dimension) {
multi_hot <- matrix(0, nrow = length(sequences), ncol = dimension)
for (i in 1:length(sequences)) {
multi_hot[i, sequences[[i]]] <- 1
}
multi_hot
}
train_data <- multi_hot_sequences(train_data, num_words)
test_data <- multi_hot_sequences(test_data, num_words)Let’s look at one of the resulting multi-hot vectors. The word indices are sorted by frequency, so it is expected that there are more 1-values near index zero, as we can see in this plot:
first_text <- data.frame(word = 1:num_words, value = train_data[1, ])
ggplot(first_text, aes(x = word, y = value)) +
geom_line() +
theme(axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank())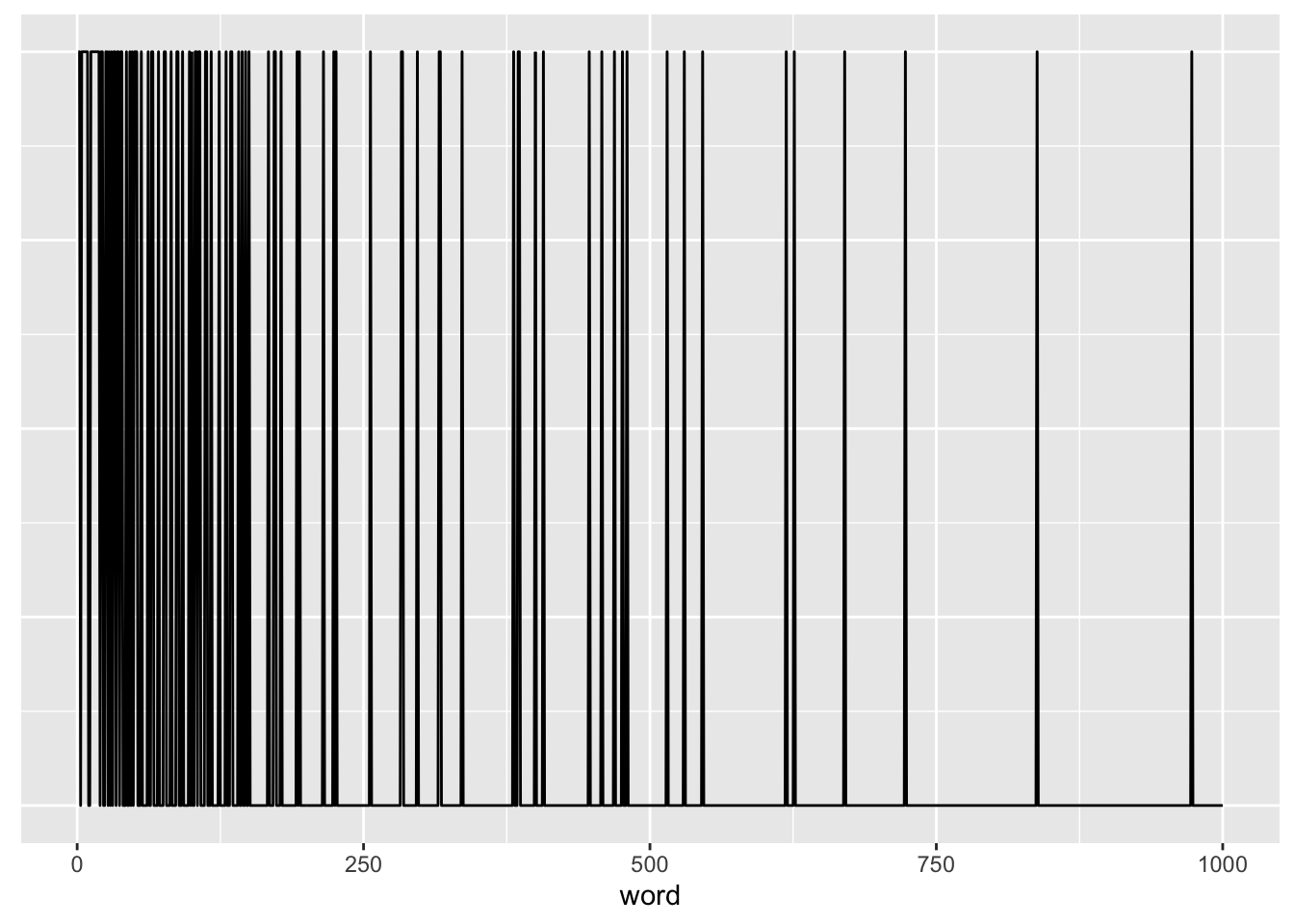
Demonstrate overfitting
The simplest way to prevent overfitting is to reduce the size of the model, i.e. the number of learnable parameters in the model (which is determined by the number of layers and the number of units per layer). In deep learning, the number of learnable parameters in a model is often referred to as the model’s “capacity”. Intuitively, a model with more parameters will have more “memorization capacity” and therefore will be able to easily learn a perfect dictionary-like mapping between training samples and their targets, a mapping without any generalization power, but this would be useless when making predictions on previously unseen data.
Always keep this in mind: deep learning models tend to be good at fitting to the training data, but the real challenge is generalization, not fitting.
On the other hand, if the network has limited memorization resources, it will not be able to learn the mapping as easily. To minimize its loss, it will have to learn compressed representations that have more predictive power. At the same time, if you make your model too small, it will have difficulty fitting to the training data. There is a balance between “too much capacity” and “not enough capacity”.
Unfortunately, there is no magical formula to determine the right size or architecture of your model (in terms of the number of layers, or what the right size for each layer). You will have to experiment using a series of different architectures.
To find an appropriate model size, it’s best to start with relatively few layers and parameters, then begin increasing the size of the layers or adding new layers until you see diminishing returns on the validation loss. Let’s try this on our movie review classification network.
We’ll create a simple model using only dense layers, then well a smaller version, and compare them.
Create a baseline model
baseline_model <-
keras_model_sequential() %>%
layer_dense(units = 16, activation = "relu", input_shape = num_words) %>%
layer_dense(units = 16, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
baseline_model %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = list("accuracy")
)
summary(baseline_model)## Model: "sequential"
## ___________________________________________________________________________
## Layer (type) Output Shape Param #
## ===========================================================================
## dense (Dense) (None, 16) 16016
## ___________________________________________________________________________
## dense_1 (Dense) (None, 16) 272
## ___________________________________________________________________________
## dense_2 (Dense) (None, 1) 17
## ===========================================================================
## Total params: 16,305
## Trainable params: 16,305
## Non-trainable params: 0
## ___________________________________________________________________________baseline_history <- baseline_model %>% fit(
train_data,
train_labels,
epochs = 20,
batch_size = 512,
validation_data = list(test_data, test_labels),
verbose = 2
)## Train on 25000 samples, validate on 25000 samples
## Epoch 1/20
## 25000/25000 - 1s - loss: 0.5966 - accuracy: 0.6998 - val_loss: 0.4544 - val_accuracy: 0.8133
## Epoch 2/20
## 25000/25000 - 0s - loss: 0.3801 - accuracy: 0.8442 - val_loss: 0.3466 - val_accuracy: 0.8547
## Epoch 3/20
## 25000/25000 - 0s - loss: 0.3243 - accuracy: 0.8650 - val_loss: 0.3322 - val_accuracy: 0.8603
## Epoch 4/20
## 25000/25000 - 0s - loss: 0.3097 - accuracy: 0.8720 - val_loss: 0.3297 - val_accuracy: 0.8601
## Epoch 5/20
## 25000/25000 - 0s - loss: 0.3041 - accuracy: 0.8752 - val_loss: 0.3286 - val_accuracy: 0.8604
## Epoch 6/20
## 25000/25000 - 0s - loss: 0.2998 - accuracy: 0.8768 - val_loss: 0.3285 - val_accuracy: 0.8604
## Epoch 7/20
## 25000/25000 - 0s - loss: 0.2971 - accuracy: 0.8779 - val_loss: 0.3297 - val_accuracy: 0.8611
## Epoch 8/20
## 25000/25000 - 0s - loss: 0.2944 - accuracy: 0.8789 - val_loss: 0.3328 - val_accuracy: 0.8583
## Epoch 9/20
## 25000/25000 - 0s - loss: 0.2910 - accuracy: 0.8805 - val_loss: 0.3301 - val_accuracy: 0.8610
## Epoch 10/20
## 25000/25000 - 0s - loss: 0.2841 - accuracy: 0.8832 - val_loss: 0.3326 - val_accuracy: 0.8605
## Epoch 11/20
## 25000/25000 - 0s - loss: 0.2784 - accuracy: 0.8858 - val_loss: 0.3321 - val_accuracy: 0.8589
## Epoch 12/20
## 25000/25000 - 0s - loss: 0.2713 - accuracy: 0.8893 - val_loss: 0.3358 - val_accuracy: 0.8576
## Epoch 13/20
## 25000/25000 - 0s - loss: 0.2631 - accuracy: 0.8929 - val_loss: 0.3433 - val_accuracy: 0.8556
## Epoch 14/20
## 25000/25000 - 0s - loss: 0.2564 - accuracy: 0.8960 - val_loss: 0.3450 - val_accuracy: 0.8529
## Epoch 15/20
## 25000/25000 - 0s - loss: 0.2481 - accuracy: 0.9007 - val_loss: 0.3502 - val_accuracy: 0.8534
## Epoch 16/20
## 25000/25000 - 0s - loss: 0.2401 - accuracy: 0.9051 - val_loss: 0.3550 - val_accuracy: 0.8516
## Epoch 17/20
## 25000/25000 - 0s - loss: 0.2330 - accuracy: 0.9086 - val_loss: 0.3634 - val_accuracy: 0.8492
## Epoch 18/20
## 25000/25000 - 0s - loss: 0.2264 - accuracy: 0.9103 - val_loss: 0.3680 - val_accuracy: 0.8476
## Epoch 19/20
## 25000/25000 - 0s - loss: 0.2201 - accuracy: 0.9133 - val_loss: 0.3747 - val_accuracy: 0.8486
## Epoch 20/20
## 25000/25000 - 0s - loss: 0.2143 - accuracy: 0.9160 - val_loss: 0.3927 - val_accuracy: 0.8444Create a smaller model
Let’s create a model with less hidden units to compare against the baseline model that we just created:
smaller_model <-
keras_model_sequential() %>%
layer_dense(units = 4, activation = "relu", input_shape = num_words) %>%
layer_dense(units = 4, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
smaller_model %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = list("accuracy")
)
summary(smaller_model)## Model: "sequential_1"
## ___________________________________________________________________________
## Layer (type) Output Shape Param #
## ===========================================================================
## dense_3 (Dense) (None, 4) 4004
## ___________________________________________________________________________
## dense_4 (Dense) (None, 4) 20
## ___________________________________________________________________________
## dense_5 (Dense) (None, 1) 5
## ===========================================================================
## Total params: 4,029
## Trainable params: 4,029
## Non-trainable params: 0
## ___________________________________________________________________________And train the model using the same data:
smaller_history <- smaller_model %>% fit(
train_data,
train_labels,
epochs = 20,
batch_size = 512,
validation_data = list(test_data, test_labels),
verbose = 2
)## Train on 25000 samples, validate on 25000 samples
## Epoch 1/20
## 25000/25000 - 0s - loss: 0.6549 - accuracy: 0.6233 - val_loss: 0.5797 - val_accuracy: 0.7310
## Epoch 2/20
## 25000/25000 - 0s - loss: 0.4872 - accuracy: 0.7950 - val_loss: 0.4280 - val_accuracy: 0.8257
## Epoch 3/20
## 25000/25000 - 0s - loss: 0.3823 - accuracy: 0.8438 - val_loss: 0.3650 - val_accuracy: 0.8489
## Epoch 4/20
## 25000/25000 - 0s - loss: 0.3415 - accuracy: 0.8603 - val_loss: 0.3439 - val_accuracy: 0.8565
## Epoch 5/20
## 25000/25000 - 0s - loss: 0.3239 - accuracy: 0.8666 - val_loss: 0.3348 - val_accuracy: 0.8589
## Epoch 6/20
## 25000/25000 - 0s - loss: 0.3142 - accuracy: 0.8715 - val_loss: 0.3320 - val_accuracy: 0.8602
## Epoch 7/20
## 25000/25000 - 0s - loss: 0.3077 - accuracy: 0.8749 - val_loss: 0.3291 - val_accuracy: 0.8604
## Epoch 8/20
## 25000/25000 - 0s - loss: 0.3031 - accuracy: 0.8752 - val_loss: 0.3286 - val_accuracy: 0.8608
## Epoch 9/20
## 25000/25000 - 0s - loss: 0.3006 - accuracy: 0.8762 - val_loss: 0.3284 - val_accuracy: 0.8608
## Epoch 10/20
## 25000/25000 - 0s - loss: 0.2976 - accuracy: 0.8788 - val_loss: 0.3294 - val_accuracy: 0.8592
## Epoch 11/20
## 25000/25000 - 0s - loss: 0.2956 - accuracy: 0.8783 - val_loss: 0.3307 - val_accuracy: 0.8595
## Epoch 12/20
## 25000/25000 - 0s - loss: 0.2927 - accuracy: 0.8808 - val_loss: 0.3303 - val_accuracy: 0.8589
## Epoch 13/20
## 25000/25000 - 0s - loss: 0.2906 - accuracy: 0.8809 - val_loss: 0.3301 - val_accuracy: 0.8598
## Epoch 14/20
## 25000/25000 - 0s - loss: 0.2877 - accuracy: 0.8827 - val_loss: 0.3312 - val_accuracy: 0.8588
## Epoch 15/20
## 25000/25000 - 0s - loss: 0.2853 - accuracy: 0.8835 - val_loss: 0.3319 - val_accuracy: 0.8584
## Epoch 16/20
## 25000/25000 - 0s - loss: 0.2829 - accuracy: 0.8841 - val_loss: 0.3341 - val_accuracy: 0.8576
## Epoch 17/20
## 25000/25000 - 0s - loss: 0.2809 - accuracy: 0.8855 - val_loss: 0.3338 - val_accuracy: 0.8577
## Epoch 18/20
## 25000/25000 - 0s - loss: 0.2791 - accuracy: 0.8855 - val_loss: 0.3372 - val_accuracy: 0.8574
## Epoch 19/20
## 25000/25000 - 0s - loss: 0.2771 - accuracy: 0.8864 - val_loss: 0.3374 - val_accuracy: 0.8565
## Epoch 20/20
## 25000/25000 - 0s - loss: 0.2758 - accuracy: 0.8866 - val_loss: 0.3380 - val_accuracy: 0.8574Create a bigger model
Next, let’s add to this benchmark a network that has much more capacity, far more than the problem would warrant:
bigger_model <-
keras_model_sequential() %>%
layer_dense(units = 512, activation = "relu", input_shape = num_words) %>%
layer_dense(units = 512, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
bigger_model %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = list("accuracy")
)
summary(bigger_model)## Model: "sequential_2"
## ___________________________________________________________________________
## Layer (type) Output Shape Param #
## ===========================================================================
## dense_6 (Dense) (None, 512) 512512
## ___________________________________________________________________________
## dense_7 (Dense) (None, 512) 262656
## ___________________________________________________________________________
## dense_8 (Dense) (None, 1) 513
## ===========================================================================
## Total params: 775,681
## Trainable params: 775,681
## Non-trainable params: 0
## ___________________________________________________________________________And, again, train the model using the same data:
bigger_history <- bigger_model %>% fit(
train_data,
train_labels,
epochs = 20,
batch_size = 512,
validation_data = list(test_data, test_labels),
verbose = 2
)## Train on 25000 samples, validate on 25000 samples
## Epoch 1/20
## 25000/25000 - 1s - loss: 0.4373 - accuracy: 0.7918 - val_loss: 0.3378 - val_accuracy: 0.8525
## Epoch 2/20
## 25000/25000 - 1s - loss: 0.2895 - accuracy: 0.8804 - val_loss: 0.3211 - val_accuracy: 0.8601
## Epoch 3/20
## 25000/25000 - 1s - loss: 0.2239 - accuracy: 0.9130 - val_loss: 0.3393 - val_accuracy: 0.8568
## Epoch 4/20
## 25000/25000 - 1s - loss: 0.1063 - accuracy: 0.9676 - val_loss: 0.4218 - val_accuracy: 0.8502
## Epoch 5/20
## 25000/25000 - 1s - loss: 0.0226 - accuracy: 0.9968 - val_loss: 0.5466 - val_accuracy: 0.8498
## Epoch 6/20
## 25000/25000 - 1s - loss: 0.0040 - accuracy: 0.9998 - val_loss: 0.6352 - val_accuracy: 0.8526
## Epoch 7/20
## 25000/25000 - 1s - loss: 0.0011 - accuracy: 1.0000 - val_loss: 0.6804 - val_accuracy: 0.8523
## Epoch 8/20
## 25000/25000 - 1s - loss: 5.5561e-04 - accuracy: 1.0000 - val_loss: 0.7107 - val_accuracy: 0.8532
## Epoch 9/20
## 25000/25000 - 1s - loss: 3.8517e-04 - accuracy: 1.0000 - val_loss: 0.7321 - val_accuracy: 0.8536
## Epoch 10/20
## 25000/25000 - 1s - loss: 2.9556e-04 - accuracy: 1.0000 - val_loss: 0.7500 - val_accuracy: 0.8532
## Epoch 11/20
## 25000/25000 - 1s - loss: 2.3442e-04 - accuracy: 1.0000 - val_loss: 0.7668 - val_accuracy: 0.8533
## Epoch 12/20
## 25000/25000 - 1s - loss: 1.9127e-04 - accuracy: 1.0000 - val_loss: 0.7805 - val_accuracy: 0.8533
## Epoch 13/20
## 25000/25000 - 1s - loss: 1.5909e-04 - accuracy: 1.0000 - val_loss: 0.7934 - val_accuracy: 0.8534
## Epoch 14/20
## 25000/25000 - 1s - loss: 1.3415e-04 - accuracy: 1.0000 - val_loss: 0.8060 - val_accuracy: 0.8532
## Epoch 15/20
## 25000/25000 - 1s - loss: 1.1400e-04 - accuracy: 1.0000 - val_loss: 0.8178 - val_accuracy: 0.8532
## Epoch 16/20
## 25000/25000 - 1s - loss: 9.7617e-05 - accuracy: 1.0000 - val_loss: 0.8299 - val_accuracy: 0.8533
## Epoch 17/20
## 25000/25000 - 1s - loss: 8.3921e-05 - accuracy: 1.0000 - val_loss: 0.8416 - val_accuracy: 0.8536
## Epoch 18/20
## 25000/25000 - 1s - loss: 7.2108e-05 - accuracy: 1.0000 - val_loss: 0.8538 - val_accuracy: 0.8536
## Epoch 19/20
## 25000/25000 - 1s - loss: 6.2046e-05 - accuracy: 1.0000 - val_loss: 0.8654 - val_accuracy: 0.8535
## Epoch 20/20
## 25000/25000 - 1s - loss: 5.3363e-05 - accuracy: 1.0000 - val_loss: 0.8779 - val_accuracy: 0.8536Plot the training and validation loss
Now, let’s plot the loss curves for the 3 models. The smaller network begins overfitting a litle later than the baseline model and its performance degrades much more slowly once it starts overfitting. Notice that the larger network begins overfitting almost right away, after just one epoch, and overfits much more severely. The more capacity the network has, the quicker it will be able to model the training data (resulting in a low training loss), but the more susceptible it is to overfitting (resulting in a large difference between the training and validation loss).
compare_cx <- data.frame(
baseline_train = baseline_history$metrics$loss,
baseline_val = baseline_history$metrics$val_loss,
smaller_train = smaller_history$metrics$loss,
smaller_val = smaller_history$metrics$val_loss,
bigger_train = bigger_history$metrics$loss,
bigger_val = bigger_history$metrics$val_loss
) %>%
rownames_to_column() %>%
mutate(rowname = as.integer(rowname)) %>%
gather(key = "type", value = "value", -rowname)
ggplot(compare_cx, aes(x = rowname, y = value, color = type)) +
geom_line() +
xlab("epoch") +
ylab("loss")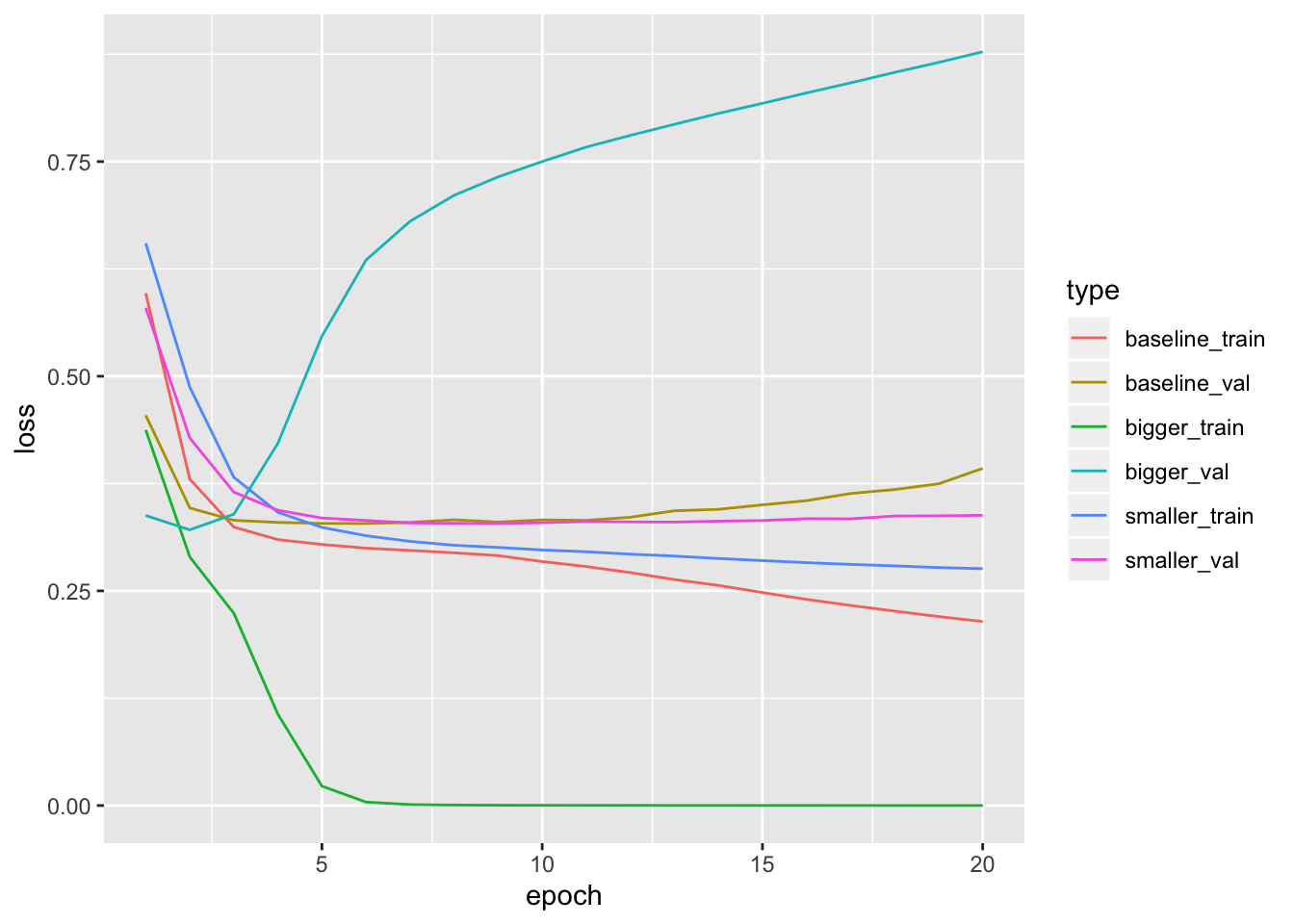
Strategies
Add weight regularization
You may be familiar with Occam’s Razor principle: given two explanations for something, the explanation most likely to be correct is the “simplest” one, the one that makes the least amount of assumptions. This also applies to the models learned by neural networks: given some training data and a network architecture, there are multiple sets of weights values (multiple models) that could explain the data, and simpler models are less likely to overfit than complex ones.
A “simple model” in this context is a model where the distribution of parameter values has less entropy (or a model with fewer parameters altogether, as we saw in the section above). Thus a common way to mitigate overfitting is to put constraints on the complexity of a network by forcing its weights to only take on small values, which makes the distribution of weight values more “regular”. This is called “weight regularization”, and it is done by adding to the loss function of the network a cost associated with having large weights. This cost comes in two flavors:
L1 regularization, where the cost added is proportional to the absolute value of the weights coefficients (i.e. to what is called the “L1 norm” of the weights).
L2 regularization, where the cost added is proportional to the square of the value of the weights coefficients (i.e. to what is called the “L2 norm” of the weights). L2 regularization is also called weight decay in the context of neural networks. Don’t let the different name confuse you: weight decay is mathematically the exact same as L2 regularization.
In Keras, weight regularization is added by passing weight regularizer instances to layers. Let’s add L2 weight regularization to the baseline model now.
l2_model <-
keras_model_sequential() %>%
layer_dense(units = 16, activation = "relu", input_shape = num_words,
kernel_regularizer = regularizer_l2(l = 0.001)) %>%
layer_dense(units = 16, activation = "relu",
kernel_regularizer = regularizer_l2(l = 0.001)) %>%
layer_dense(units = 1, activation = "sigmoid")
l2_model %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = list("accuracy")
)
l2_history <- l2_model %>% fit(
train_data,
train_labels,
epochs = 20,
batch_size = 512,
validation_data = list(test_data, test_labels),
verbose = 2
)## Train on 25000 samples, validate on 25000 samples
## Epoch 1/20
## 25000/25000 - 1s - loss: 0.6101 - accuracy: 0.7228 - val_loss: 0.4664 - val_accuracy: 0.8261
## Epoch 2/20
## 25000/25000 - 0s - loss: 0.4045 - accuracy: 0.8495 - val_loss: 0.3843 - val_accuracy: 0.8546
## Epoch 3/20
## 25000/25000 - 0s - loss: 0.3595 - accuracy: 0.8669 - val_loss: 0.3688 - val_accuracy: 0.8609
## Epoch 4/20
## 25000/25000 - 0s - loss: 0.3470 - accuracy: 0.8728 - val_loss: 0.3686 - val_accuracy: 0.8596
## Epoch 5/20
## 25000/25000 - 0s - loss: 0.3401 - accuracy: 0.8745 - val_loss: 0.3614 - val_accuracy: 0.8612
## Epoch 6/20
## 25000/25000 - 0s - loss: 0.3356 - accuracy: 0.8751 - val_loss: 0.3612 - val_accuracy: 0.8592
## Epoch 7/20
## 25000/25000 - 0s - loss: 0.3329 - accuracy: 0.8763 - val_loss: 0.3576 - val_accuracy: 0.8600
## Epoch 8/20
## 25000/25000 - 0s - loss: 0.3290 - accuracy: 0.8771 - val_loss: 0.3582 - val_accuracy: 0.8592
## Epoch 9/20
## 25000/25000 - 0s - loss: 0.3253 - accuracy: 0.8780 - val_loss: 0.3601 - val_accuracy: 0.8584
## Epoch 10/20
## 25000/25000 - 0s - loss: 0.3229 - accuracy: 0.8790 - val_loss: 0.3558 - val_accuracy: 0.8594
## Epoch 11/20
## 25000/25000 - 0s - loss: 0.3196 - accuracy: 0.8812 - val_loss: 0.3560 - val_accuracy: 0.8597
## Epoch 12/20
## 25000/25000 - 0s - loss: 0.3147 - accuracy: 0.8831 - val_loss: 0.3570 - val_accuracy: 0.8588
## Epoch 13/20
## 25000/25000 - 0s - loss: 0.3099 - accuracy: 0.8856 - val_loss: 0.3589 - val_accuracy: 0.8584
## Epoch 14/20
## 25000/25000 - 0s - loss: 0.3056 - accuracy: 0.8874 - val_loss: 0.3590 - val_accuracy: 0.8577
## Epoch 15/20
## 25000/25000 - 0s - loss: 0.3002 - accuracy: 0.8919 - val_loss: 0.3596 - val_accuracy: 0.8576
## Epoch 16/20
## 25000/25000 - 0s - loss: 0.2931 - accuracy: 0.8954 - val_loss: 0.3665 - val_accuracy: 0.8558
## Epoch 17/20
## 25000/25000 - 0s - loss: 0.2880 - accuracy: 0.8993 - val_loss: 0.3683 - val_accuracy: 0.8552
## Epoch 18/20
## 25000/25000 - 0s - loss: 0.2838 - accuracy: 0.9012 - val_loss: 0.3731 - val_accuracy: 0.8540
## Epoch 19/20
## 25000/25000 - 0s - loss: 0.2781 - accuracy: 0.9044 - val_loss: 0.3830 - val_accuracy: 0.8526
## Epoch 20/20
## 25000/25000 - 0s - loss: 0.2754 - accuracy: 0.9070 - val_loss: 0.3877 - val_accuracy: 0.8514l2(0.001) means that every coefficient in the weight matrix of the layer will add 0.001 * weight_coefficient_value to the total loss of the network. Note that because this penalty is only added at training time, the loss for this network will be much higher at training than at test time.
Here’s the impact of our L2 regularization penalty:
compare_cx <- data.frame(
baseline_train = baseline_history$metrics$loss,
baseline_val = baseline_history$metrics$val_loss,
l2_train = l2_history$metrics$loss,
l2_val = l2_history$metrics$val_loss
) %>%
rownames_to_column() %>%
mutate(rowname = as.integer(rowname)) %>%
gather(key = "type", value = "value", -rowname)
ggplot(compare_cx, aes(x = rowname, y = value, color = type)) +
geom_line() +
xlab("epoch") +
ylab("loss")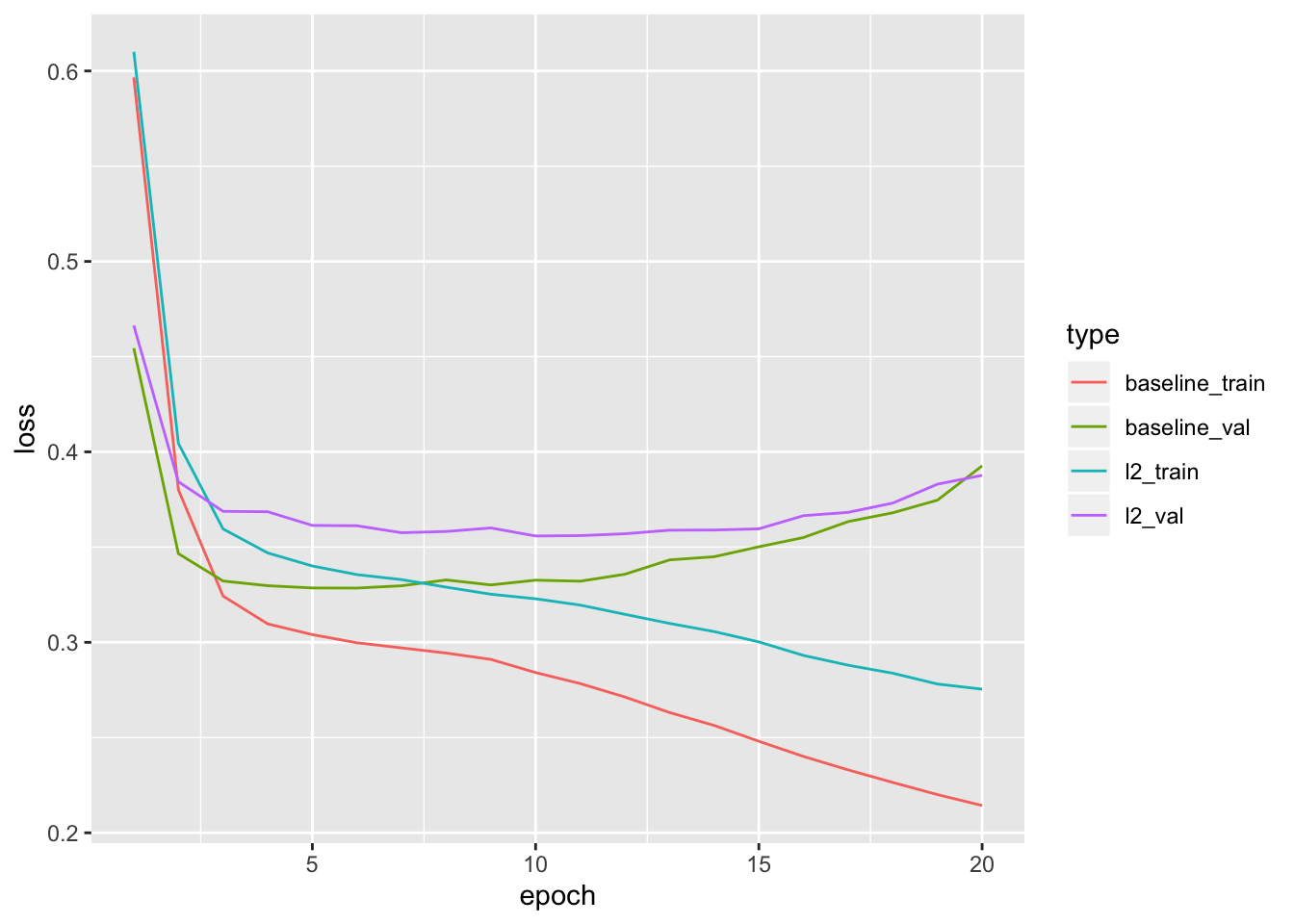
As you can see, the L2 regularized model has become much more resistant to overfitting than the baseline model, even though both models have the same number of parameters.
Add dropout
Dropout is one of the most effective and most commonly used regularization techniques for neural networks, developed by Hinton and his students at the University of Toronto. Dropout, applied to a layer, consists of randomly “dropping out” (i.e. set to zero) a number of output features of the layer during training. Let’s say a given layer would normally have returned a vector [0.2, 0.5, 1.3, 0.8, 1.1] for a given input sample during training; after applying dropout, this vector will have a few zero entries distributed at random, e.g. [0, 0.5, 1.3, 0, 1.1]. The “dropout rate” is the fraction of the features that are being zeroed-out; it is usually set between 0.2 and 0.5. At test time, no units are dropped out, and instead the layer’s output values are scaled down by a factor equal to the dropout rate, so as to balance for the fact that more units are active than at training time.
In Keras you can introduce dropout in a network via layer_dropout, which gets applied to the output of the layer right before.
Let’s add two dropout layers in our IMDB network to see how well they do at reducing overfitting:
dropout_model <-
keras_model_sequential() %>%
layer_dense(units = 16, activation = "relu", input_shape = num_words) %>%
layer_dropout(0.6) %>%
layer_dense(units = 16, activation = "relu") %>%
layer_dropout(0.6) %>%
layer_dense(units = 1, activation = "sigmoid")
dropout_model %>% compile(
optimizer = "adam",
loss = "binary_crossentropy",
metrics = list("accuracy")
)
dropout_history <- dropout_model %>% fit(
train_data,
train_labels,
epochs = 20,
batch_size = 512,
validation_data = list(test_data, test_labels),
verbose = 2
)## Train on 25000 samples, validate on 25000 samples
## Epoch 1/20
## 25000/25000 - 1s - loss: 0.6934 - accuracy: 0.5353 - val_loss: 0.6712 - val_accuracy: 0.6958
## Epoch 2/20
## 25000/25000 - 0s - loss: 0.6501 - accuracy: 0.6097 - val_loss: 0.5780 - val_accuracy: 0.7938
## Epoch 3/20
## 25000/25000 - 0s - loss: 0.5877 - accuracy: 0.6693 - val_loss: 0.4819 - val_accuracy: 0.8246
## Epoch 4/20
## 25000/25000 - 0s - loss: 0.5306 - accuracy: 0.7283 - val_loss: 0.4093 - val_accuracy: 0.8453
## Epoch 5/20
## 25000/25000 - 0s - loss: 0.4874 - accuracy: 0.7715 - val_loss: 0.3806 - val_accuracy: 0.8492
## Epoch 6/20
## 25000/25000 - 0s - loss: 0.4545 - accuracy: 0.8026 - val_loss: 0.3476 - val_accuracy: 0.8573
## Epoch 7/20
## 25000/25000 - 0s - loss: 0.4322 - accuracy: 0.8235 - val_loss: 0.3407 - val_accuracy: 0.8574
## Epoch 8/20
## 25000/25000 - 0s - loss: 0.4163 - accuracy: 0.8289 - val_loss: 0.3311 - val_accuracy: 0.8594
## Epoch 9/20
## 25000/25000 - 0s - loss: 0.4061 - accuracy: 0.8338 - val_loss: 0.3323 - val_accuracy: 0.8583
## Epoch 10/20
## 25000/25000 - 0s - loss: 0.3927 - accuracy: 0.8413 - val_loss: 0.3268 - val_accuracy: 0.8592
## Epoch 11/20
## 25000/25000 - 0s - loss: 0.3893 - accuracy: 0.8441 - val_loss: 0.3278 - val_accuracy: 0.8586
## Epoch 12/20
## 25000/25000 - 0s - loss: 0.3829 - accuracy: 0.8460 - val_loss: 0.3242 - val_accuracy: 0.8602
## Epoch 13/20
## 25000/25000 - 0s - loss: 0.3800 - accuracy: 0.8467 - val_loss: 0.3254 - val_accuracy: 0.8582
## Epoch 14/20
## 25000/25000 - 0s - loss: 0.3749 - accuracy: 0.8538 - val_loss: 0.3265 - val_accuracy: 0.8581
## Epoch 15/20
## 25000/25000 - 0s - loss: 0.3706 - accuracy: 0.8533 - val_loss: 0.3259 - val_accuracy: 0.8586
## Epoch 16/20
## 25000/25000 - 0s - loss: 0.3689 - accuracy: 0.8546 - val_loss: 0.3263 - val_accuracy: 0.8591
## Epoch 17/20
## 25000/25000 - 0s - loss: 0.3626 - accuracy: 0.8580 - val_loss: 0.3265 - val_accuracy: 0.8574
## Epoch 18/20
## 25000/25000 - 0s - loss: 0.3644 - accuracy: 0.8555 - val_loss: 0.3272 - val_accuracy: 0.8581
## Epoch 19/20
## 25000/25000 - 0s - loss: 0.3600 - accuracy: 0.8590 - val_loss: 0.3284 - val_accuracy: 0.8558
## Epoch 20/20
## 25000/25000 - 0s - loss: 0.3569 - accuracy: 0.8591 - val_loss: 0.3294 - val_accuracy: 0.8591How well did it work?
compare_cx <- data.frame(
baseline_train = baseline_history$metrics$loss,
baseline_val = baseline_history$metrics$val_loss,
dropout_train = dropout_history$metrics$loss,
dropout_val = dropout_history$metrics$val_loss
) %>%
rownames_to_column() %>%
mutate(rowname = as.integer(rowname)) %>%
gather(key = "type", value = "value", -rowname)
ggplot(compare_cx, aes(x = rowname, y = value, color = type)) +
geom_line() +
xlab("epoch") +
ylab("loss")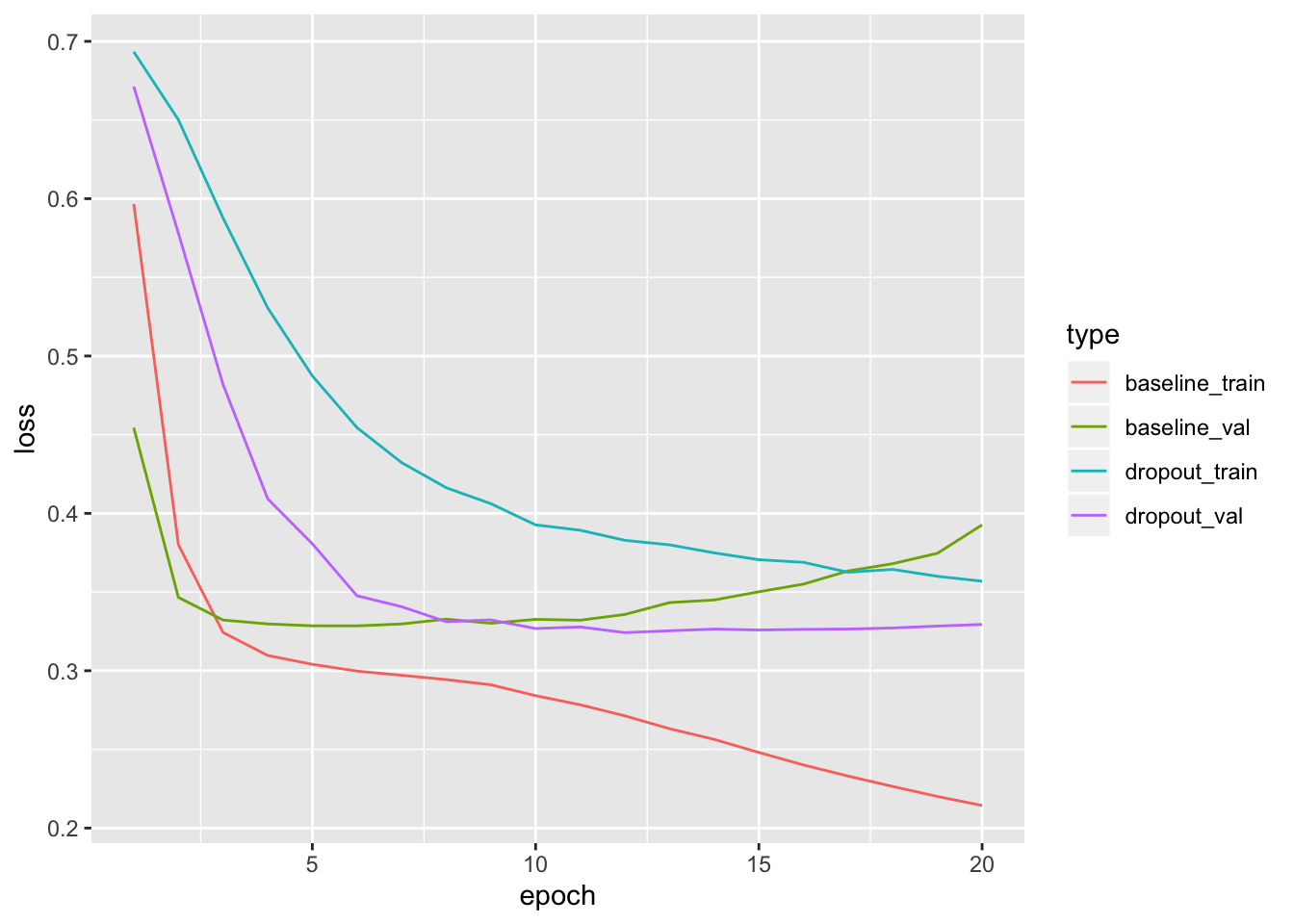
Adding dropout is a clear improvement over the baseline model.
To recap: here the most common ways to prevent overfitting in neural networks:
- Get more training data.
- Reduce the capacity of the network.
- Add weight regularization.
- Add dropout.
And two important approaches not covered in this guide are data augmentation and batch normalization.